最近スパムメールが多いと思ったら、スパムフィルターのbsfilterが動いてませんでした(汗)。
調べてみたら、rubyからmecabが動いておらず、それはmecabの辞書がutf-8でなかったの原因でした。
bsfilterはかなり前にインストールしたものです。その後、文字のエンコーディングの扱いがutf-8になったのでしょう。 ぼくのbsfilterのdbは2015年の11月を最後に更新されていません(泣)。
基本的はmecabの辞書をutf-8にすればbsfilterは問題なく動くようです。以下は調べた顛末です。
目次
bsfilter ってなに?
Rubyで書かれたスパムメールフィルターです。
ベイズ統計を用いてスパムメールかどうかを判定しています。判定には事前の学習が必要です。
判定する時にメール本文をtoken化(品詞毎に切り出し)しています。そのtoken化するエンジンは選択肢があって、その一つがmecabです。
もっと雑(ごめんなさい)なtoken化エンジンもあって、連続した漢字二文字をtokenとするものもあります。 スパム判定の精度を上げるには、このtoken化が大事かなと思いますが、調査したわけではありません。
トラブルシューティングの顛末
スパムが学習できるか
まずはスパムを学習させます。すると
~% bsfilter --add-spam ~/Maildir/.spam/cur/* /usr/bin/bsfilter:1029:in `initialize': unhandled exception from /usr/bin/bsfilter:1029:in `new' from /usr/bin/bsfilter:1029:in `initialize' from /usr/bin/bsfilter:3130:in `new' from /usr/bin/bsfilter:3130:in `get_options' from /usr/bin/bsfilter:3262:in `setup' from /usr/bin/bsfilter:3413:in `'
のようにエラーがでます。この1029行目は
m = MeCab::Tagger.new("-Ochasen")
のような文で、要するにMeCabでエラーになっているようです。
MeCabのエラーの原因調査
mecab ruby バインディングのサンプルを https://taku910.github.io/mecab/bindings.html を参考に作ってみたのが下のコードです。
#!/usr/bin/ruby # coding: utf-8 require 'MeCab' m = MeCab::Tagger.new("-Ochasen") print m.parse("今日もちゃんとしないとね")
しかし、これが動かないのです。MeCab::Tagger.newを
m = MeCab::Tagger.new("")
にすれば動くのですが、結果はは文字化けです。
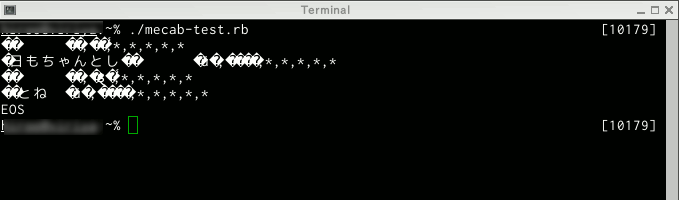
文字化けですから、文字コードが関連していることが想像できます。この時はmecabの辞書は /var/lib/mecab/dic/juman でした。 これを /var/lib/mecab/dic/ipadic-utf8 に変更します。
mecabの辞書をutf-8に変更してテスト
~% sudo update-alternatives --config mecab-dictionary There are 4 choices for the alternative mecab-dictionary (providing /var/lib/mecab/dic/debian). Selection Path Priority Status ------------------------------------------------------------ 0 /var/lib/mecab/dic/ipadic-utf8 80 auto mode 1 /var/lib/mecab/dic/ipadic 70 manual mode 2 /var/lib/mecab/dic/ipadic-utf8 80 manual mode * 3 /var/lib/mecab/dic/juman 30 manual mode 4 /var/lib/mecab/dic/juman-utf8 40 manual mode Pressto keep the current choice[*], or type selection number: 0 update-alternatives: using /var/lib/mecab/dic/ipadic-utf8 to provide /var/lib/mecab/dic/debian (mecab-dictionary) in auto mode
これで上のコードは動くようになります。
~% ./mecab-test.rb 今日 名詞,副詞可能,*,*,*,*,今日,キョウ,キョー も 助詞,係助詞,*,*,*,*,も,モ,モ ちゃんと 副詞,一般,*,*,*,*,ちゃんと,チャント,チャント し 動詞,自立,*,*,サ変・スル,未然形,する,シ,シ ない 助動詞,*,*,*,特殊・ナイ,基本形,ない,ナイ,ナイ と 助詞,接続助詞,*,*,*,*,と,ト,ト ね 助詞,終助詞,*,*,*,*,ね,ネ,ネ EOS
さらにm = MeCab::Tagger.new("-Ochasen")に戻すと
~% ./mecab-test.rb 今日 キョウ 今日 名詞-副詞可能 も モ も 助詞-係助詞 ちゃんと チャント ちゃんと 副詞-一般 し シ する 動詞-自立 サ変・スル 未然形 ない ナイ ない 助動詞 特殊・ナイ 基本形 と ト と 助詞-接続助詞 ね ネ ね 助詞-終助詞 EOS
のように、こちらも動きます。
これでbsfilterもちゃんと動作します。
おまけ: bsfilterの設定
bsfilterの設定を以下に示します。
~/.bsfilter/bsfilter.conf
bsfilterはtoken化にmecab、dbはgdbmを指定しています。
## example of bsfilter.conf jtokenizer MeCab db gdbm
~/.procmailrc
ぼくは設定ファイルが分かりづらいことで悪名高い(笑) procmail を使っています。
設定は以下の通りです。判定結果をメールのヘッダーに挿入して、その判定したスパム確率に応じてspam, spam-maybe フォルダに振分けています。
# bsfilter :0 fw | /usr/bin/bsfilter --pipe --insert-flag --insert-probability --auto-update :0 * ^X-Spam-Probability: *(1|0.[89]) .spam/ :0 * ^X-Spam-Probability: *0.[567] .spam-maybe/ # :0 * .* $HOME/Maildir/